Tip #1: Index All Columns Used in 'where', 'order by', and 'group by' Clauses
Though indexes may take up more space and decrease performance on inserts, deletes, and updates.
However, indexes can considerably reduce select query execution time.
without index => full table scan
mysql> select customer_name from customers where customer_id='140385';
The above query will force Database server to conduct a full table scan (start to finish) to retrieve the record that we are searching.
Database server has a special
'EXPLAIN' statement that you can use alongside select, delete, insert, replace and update statements to analyze your queries.
Once you append the query before an SQL statement,
mysql>
explain select customer_id, customer_name from customers where customer_id='140385';
Server displays information from the optimizer about the intended execution plan.
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | customers | NULL | ALL | NULL |
NULL | NULL | NULL |
500 | 10.00 |
Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
As you can see, the optimizer has displayed very important information that can help us to fine-tune our database table.
First, it is clear that MySQL will conduct a full table scan because key column is 'NULL'.
Second, MySQL server has clearly indicated that it's going to conduct a full scan on the 500 rows in our database.
To optimize the above query, we can just add an index to the 'customer_id' field.
If we run the explain statement one more time, we will get the below results:
mysql> Explain select customer_id, customer_name from customers where customer_id='140385';
+----+-------------+-----------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | customers | NULL | ref | customer_id |
customer_id | 13 | const |
1 | 100.00 | NULL |
+----+-------------+-----------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
From the above explain output, it's clear that MySQL server will use our index (customer_Id) to search the table.
You can clearly see that the number of rows to scan will be 1. Although I run the above query in a table with 500 records, indexes can be very useful when you are querying a large dataset (e.g. a table with 1 million rows).
Tip 2: Optimize Like Statements With Union Clause
Sometimes, you may want to run queries using the comparison operator 'or' on different fields or columns in a particular table. When the 'or' keyword is used too much in where clause, it might make the MySQL optimizer to incorrectly choose a full table scan to retrieve a record.
A union clause can make the query run faster especially if you have an index that can optimize one side of the query and a different index to optimize the other side.
Example, consider a case where you are running the below query with the 'first_name' and 'last_name' indexed:
mysql> select * from students where first_name like 'Ade%'
OR last_name like 'Ade%' ;
The query above can run far much slower compared to the below query which uses a union operator merge the results of 2 separate fast queries that takes advantage of the indexes.
mysql> select from students where first_name like 'Ade%'
UNION ALL select from students where last_name like 'Ade%' ;
Tip 3: Avoid Like Expressions With Leading Wildcards
MySQL is not able to utilize
indexes when there is a
leading wildcard in a query. If we take our example above on the students table, a search like this will cause MySQL to
perform full table scan even if you have indexed the 'first_name' field on the students table.
mysql> select * from students where first_name like '%Ade' ;
We can prove this using the explain keyword:
mysql> explain select * from students where
first_name like '%Ade' ;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | students | NULL | ALL | NULL | NULL | NULL | NULL | 500 | 11.11 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
As you can see above, MySQL is going to scan all the 500 rows in our students table and make will make the query extremely slow.
Tip 4: Take Advantage of MySQL Full-Text Searches
If you are faced with a situation where you need to search data using wildcards and you don't want your database to underperform, you should consider using MySQL full-text search (FTS) because it is far much faster than queries using wildcard characters.
Furthermore, FTS can also bring better and relevant results when you are searching a huge database.
To add a full-text search index to the students sample table, we can use the below MySQL command:
mysql>
Alter table students ADD FULLTEXT (first_name, last_name);
mysql>
Select * from students where match(first_name, last_name) AGAINST ('Ade');
In the above example, we have specified the columns that we want to be matched (first_name and last_name) against our search keyword ('Ade').
If we query the optimizer about the execution plan of the above query, we will get the following results:
mysql> explain Select * from students where match(first_name, last_name) AGAINST ('Ade');
+----+-------------+----------+------------+----------+---------------+------------+---------+-------+------+----------+-------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+----------+---------------+------------+---------+-------+------+----------+-------------------------------+
| 1 | SIMPLE | students | NULL | fulltext | first_name | first_name | 0 | const | 1 | 100.00 | Using where; Ft_hints: sorted |
+----+-------------+----------+------------+----------+---------------+------------+---------+-------+------+----------+-------------------------------+
It's clear that only a single row will be scanned even if our student's database has 500 rows and this will speed up the database.
LIKE vs CONTAINS on SQL Server
Which one of the following queries is faster (LIKE vs CONTAINS)?
SELECT * FROM table WHERE Column LIKE '%test%';
or
SELECT * FROM table WHERE Contains(Column, "test");
The second should be faster, because it can use some form of index (in this case, a
full text index).
Of course, this form of query is only available if the column is in a full text index. If it isn't, then only the first form is available.
The first query, using LIKE, will be unable to use an index, since it starts with a wildcard, so will always require a full table scan.
***********************************************************************
Optimize Your Database Schema
Even if you optimize your MySQL queries and fail to come up with a good database structure, your database performance can still halt when your data increases.
Normalize Tables
First, normalize all database tables even if it will involve some trade-offs. For instance, if you are creating two tables to hold customers data and orders,
you should reference the customer on the orders table using the customer id as opposed to repeating the customer's name on the orders table. The latter will cause your database to bloat.
The image below refers to a database schema that is designed for performance without any data redundancy. In MySQL database normalization, you should represent a fact only once in the entire database. Don't repeat the customer name in every table; instead just use the customer_Id for reference in other tables.
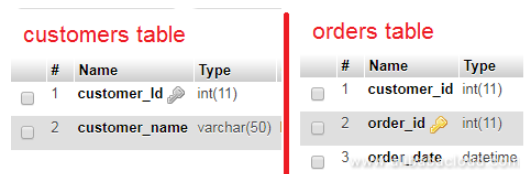
Also,
always use the same data type for storing similar values even if they are on different tables, for instance, the schema above uses 'INT' data type to store 'customer_id' both in the customers and orders table.
Use Optimal Data Types
MySQL supports different data types including integer, float, double, date, date_time, Varchar, and text, among others. When designing your tables, you should know that "shorter is always better."
For instances, if you are designing a system user's
table which will hold less than 100 users, you should use
'TINYINT' data type for the 'user_id' field because it will accommodate all your values from -128 to 128.
Also,
if a field expects a date value (e.g. sales_order_date), using a date_time data type will be ideal because you don't have to run complicated functions to convert the field to date when retrieving records using SQL.
Use integer values if you expect all values to be numbers (e.g. in a student_id or a payment_id field). Remember, when it comes to computation, MySQL can do better with integer values as compared to text data types such as Varchar
Avoid Null Values
Null is the absence of any value in a column. You should avoid this kind of values whenever possible because they can harm your database results. For instance,
if you want to get the sum of all orders in a database but a particular order record has a null amount, the expected result might misbehave unless you use MySQL 'ifnull' statement to return alternative value if a record is null.
In some cases, you might need to
define a default value for a field if records don't have to include a mandatory value for that particular column/field.
Avoid Too Many Columns
Wide tables can be extremely expensive and require more CPU time to process. If possible, don't go above a hundred unless your business logic specifically calls for this.
Instead of creating one wide table, consider splitting it apart in to logical structures. For instance, if you are creating a customer table but you realize a customer can have multiple addresses, it is better to create a separate table for holding customers addresses that refer back to the customers table using the 'customer_id' field.
Optimize Joins
Always include fewer tables in your join statements. An SQL statement with poorly designed pattern that involves a lot of joins may not work well. A rule of thumb is to have utmost a dozen joins for each query.
MySQL Query Caching
If your website or application performs a lot of select queries (e.g. WordPress), you should take advantage of MySQL query caching feature. This will speed up performance when read operations are conducted.
The technology works by caching the select query alongside the resulting data set. This makes the query run faster since they are fetched from memory if they are executed more than once. However, if your application updates the table frequently, this will invalidate any cached query and result set.
You can check if your MySQL server has query cache enabled by running the command below:
mysql> show variables like 'have_query_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | YES |
+------------------+-------+
1 row in <b>set</b> (0.00 sec)
Setting the MySQL Server Query Cache
You can set the MySQL query cache values by editing the configuration file ('/etc/mysql/my.cnf' or '/etc/mysql/mysql.conf.d/mysqld.cnf'). This will depend on your MySQL installation. Don't set a very large query cache size value because this will degrade the MySQL server due to cached overhead and locking. Values in the range of tens of megabytes are recommended.
To check the current value, use the command below:
mysql> show variables like 'query_cache_%' ;
+------------------------------+----------+
| Variable_name | Value |
+------------------------------+----------+
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 16777216 |
| query_cache_type | OFF |
| query_cache_wlock_invalidate | OFF |
+------------------------------+----------+
5 rows in <b>set</b> (0.00 sec)
Then to adjust the values, include the following on the MySQL configuration file:
query_cache_type=1
query_cache_size = 10M
query_cache_limit=256k
You can adjust the above values according to your server needs.
The directive 'query_cache_type=1' turns MySQL caching on if it was turned off by default.
The default 'query_cache_size' is 1MB and like we said above a value a range of around 10 MB is recommended. Also, the value must be over 40 KB otherwise MySQL server will throw a warning, "Query cache failed to set size".
The default 'query_cache_limit' is also 1MB. This value controls the amount of individual query result that can be can be cached.