JMS API is a Java message-oriented middleware API which contains a common set of interfaces to implement enterprise based messaging systems.
Benefit of using JMS are – loosely coupled application, reliability, and asynchronous communication between applications using JMS
ActiveMQ/ RabbitMQ is a popular message broker typically used for building integration between applications or different components of the same application using messages.
What is Message?
The message is a piece of information. It can be a text, XML document, JSON data or an Entity (Java Object) etc. The message is very useful data to communicate between different systems.
3 parts of message are:-
a)header :- It contains a number of predefined fields using for proper delivery and routing.
b)body :- As the name suggests it is the body of messages. JMS API allows five types of message bodies.
1.TextMessage :- Body contains String data
2.ByteMessage :- Body contains byte data
3. MapMessage :- Body contains data in key/value pair
4.StreamMessage :-Body contains a stream of primitive values
5.ObjectMessage : – Body contains an object
6.Message :- Nothing in body. Only header and properties.
c)properties :- Additional properties other than header.

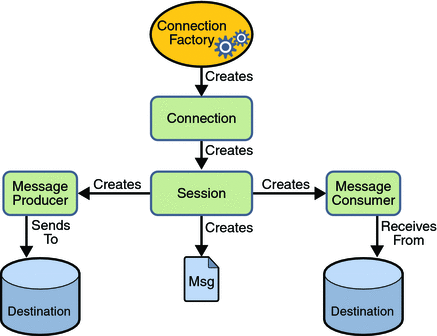
JMS Architecture
How to Create a Simple JMS Queue in Weblogic Server 11g?
Create a JMS Server
Services > Messaging > JMS Servers
Select New ->
Name: TestJMSServer
Persistent Store: (none)
Target: soa_server1 (or choose an available server)
Finish

The JMS server should now be visible in the list with Health OK.

Create a JMS Module
Services > Messaging > JMS Modules
Select New ->
Name: TestJMSModule
Leave the other options empty
Target: soa_server1 (or choose an available server)
Leave “Would you like to add resources to this JMS system
module” unchecked
Finish
Create a JMS SubDeployment
Services > Messaging > JMS Modules
Select -> TestJMSModule
Select the Subdeployments tab and New ->
Name: TestSubdeployment
Next
Here you can select the target(s) for the subdeployment. You can
choose either Servers (i.e. WebLogic managed servers, such as the
soa_server1) or JMS Servers such as the JMS Server created
earlier. As the purpose of our subdeployment in this example is to
target a specific JMS server, we will choose the JMS Server option.
Select theTestJMSServer created earlier
Finish
Create a JMS Queue

The JMS queue is now complete and can be accessed using the JNDI names
jms/TestConnectionFactory
jms/TestJMSQueue.
Send a Message to a JMS Queue?
import javax.jms.*;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
String url = "";
public final static String JNDI_FACTORY="weblogic.jndi.WLInitialContextFactory";
public final static String JMS_FACTORY="jms/TestConnectionFactory";
public final static String QUEUE="jms/TestJMSQueue";
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
InitialContext ic = new InitialContext(env);
QueueConnectionFactory qconFactory = (QueueConnectionFactory) ctx.lookup(JMS_FACTORY);
QueueConnection qcon = qconFactory.createQueueConnection();
QueueSession qsession = qcon.createQueueSession(false, Session.AUTO_ACKNOWLEDGE);
Queue queue = (Queue) ctx.lookup(QUEUE);
QueueSender qsender = qsession.createSender(queue);
TextMessage msg = qsession.createTextMessage();
msg.setText(message);
qcon.start();
qsender.send(msg);
qsender.close();
qsession.close();
qcon.close();
Receive a Message from a JMS Queue?
import javax.jms.*;
public class MyListener implements MessageListener {
public void onMessage(Message m) {
try{
TextMessage msg=(TextMessage)m;
System.out.println("following message is received:"+msg.getText());
}catch(JMSException e){System.out.println(e);}
}
}
Receive a Message from a JMS Queue?
import javax.jms.*;
public class MyListener implements MessageListener {
public void onMessage(Message m) {
try{
TextMessage msg=(TextMessage)m;
System.out.println("following message is received:"+msg.getText());
}catch(JMSException e){System.out.println(e);}
}
}
createQueueSession(false, Session.AUTO_ACKNOWLEDGE);
true -> transacted [commit(), rollback()]
false -> non -transacted
AUTO_ACKNOWLEDGE
CLIENT_ACKNOWLEDGE
DUPS_OK_ACKNOWLEDGE
JMS API supports the sending of any Serializable object as ObjectMessage object .
how an object is sent as a message between two client applications.
FirstClient.java creates an EventMessage object and sends it to the destination.
SecondClient.java is receiving the same EventMessage object from the same destination.
public class EventMessage implements Serializable {
private static final long serialVersionUID = 1L;
private int messageId;
private String messageText = "";
public EventMessage(int id, String messageText) {
this.messageId = id;
this.messageText = messageText;
}
producer = session.createProducer(destination);
EventMessage eventMessage = new EventMessage(1,"Message from FirstClient");
ObjectMessage objectMessage = session.createObjectMessage();
objectMessage.setObject(eventMessage);
producer.send(objectMessage);
consumer = session.createConsumer(destination);
Message message = consumer.receive();
if (message instanceof ObjectMessage) {
Object object = ((ObjectMessage) message).getObject();
System.out.println(this.getClass().getName()
+ "has received a message : " + (EventMessage) object);