
The definition of persistence can be given like this, “Data that can be stored to some permanent medium and can be seen at any point of time even after the application that created the data has ended”. Persisting (or preserving) data is not an easy task and it is one of the basic necessities for almost any application. The common storage mediums that we see in our day-to-day life are hard-disk and a database.
JDBC stands for Java Database Connectivity and provides a set of Java API for accessing the relational databases from Java program. These Java APIs enables Java programs to execute SQL statements and interact with any SQL compliant database.
ORM stands for Object-Relational Mapping (ORM) is a programming technique for converting data between relational databases and object oriented programming languages.
There are several persistent frameworks and ORM options in Java. A persistent framework is an ORM service that stores and retrieves objects into a relational database.
- Enterprise JavaBeans Entity Beans
- Java Data Objects
- Castor
- TopLink
- Spring DAO
- Hibernate
Hibernate is one of the Object-Relational Mapping tool for persisting and querying data. Most of the Hibernate features look very similar that are found in Java Persistence API (JPA) specification. Also Hibernate provides some add-on functionalities that are not mentioned in the JPA specification.Hibernate doesn’t replace JDBC. Hibernate is sitting on top of JDBC to connect to the database. Internally Hibernate is using these JDBC calls to connect to the database systems.
Hibernate can well integrate with all kinds any of J2SE/J2EE application and with any kind of frameworks (like Spring, Struts etc).

Configuration Object:
The Configuration object is the first Hibernate object you create in any Hibernate application and usually created only once during application initialization. It represents a configuration or properties file required by the Hibernate. The Configuration object provides two keys components:
- Database Connection: This is handled through one or more configuration files supported by Hibernate. These files are hibernate.properties andhibernate.cfg.xml.
- Class Mapping Setup
This component creates the connection between the Java classes and database tables..
SessionFactory Object:
Configuration object is used to create a SessionFactory object which in turn configures Hibernate for the application using the supplied configuration file and allows for a Session object to be instantiated. The SessionFactory is a thread safe object and used by all the threads of an application.
The SessionFactory is heavyweight object so usually it is created during application start up and kept for later use. You would need one SessionFactory object per database using a separate configuration file. So if you are using multiple databases then you would have to create multiple SessionFactory objects.
Session Object:
A Session is used to get a physical connection with a database. The Session object is lightweight and designed to be instantiated each time an interaction is needed with the database. Persistent objects are saved and retrieved through a Session object.
The session objects should not be kept open for a long time because they are not usually thread safe and they should be created and destroyed them as needed.
Transaction Object:
A Transaction represents a unit of work with the database and most of the RDBMS supports transaction functionality. Transactions in Hibernate are handled by an underlying transaction manager and transaction (from JDBC or JTA).
This is an optional object and Hibernate applications may choose not to use this interface, instead managing transactions in their own application code.
Query Object:
Query objects use SQL or Hibernate Query Language (HQL) string to retrieve data from the database and create objects. A Query instance is used to bind query parameters, limit the number of results returned by the query, and finally to execute the query.
Criteria Object:
Criteria object are used to create and execute object oriented criteria queries to retrieve objects.
Hibernate Properties:
hibernate.dialect This property makes Hibernate generate the appropriate SQL for the chosen database.
hibernate.connection.driver_class The JDBC driver class.
hibernate.connection.url The JDBC URL to the database instance.
hibernate.connection.username The database username.
hibernate.connection.password The database password.
hibernate.connection.pool_size Limits the number of connections waiting in the Hibernate database connection pool.
hibernate.connection.autocommit Allows autocommit mode to be used for the JDBC connection.
Hibernate Modules
Hibernate Core which represent the basic and the core module of the Hibernate project provides support for OO features along with the Query services.
Another module called Hibernate JPA is an implementation for the specification“Java Persistence API (JPA)” from Sun and we can be used in any Sun’s compliant Application Server as well as with J2SE applications.
There is a separate module called Hibernate Search that provides rich functionality for searching the persistence domain model using a simplified API.
For validating the data, Hibernate comes with a set of validation rules in the form of Annotations in a module called Hibernate validations and it also allows the developers to create custom validation rules.
Support for Querying and inserting data from multiple databases can be achieved by using the Hibernate Shards API.
Configuration and Mapping Files
An application that uses Hibernate API must use a single configuration file. A configuration file for a Hibernate application will tell some of the information like the URL of the Database Server to which the application wants to connect, the username/password for the Database, class name of the Driver file and with other set of preferences.
A Hibernate configuration file can be an XML-based file (hibernate.cfg.xml) or it can be ordinary Java properties file (hibernate.properties) with key-value combination. This configuration file should be placed in the run-time classpath of an application. If both the XML-based configuration file and the properties-based configuration file are found in the classpath, then the XML-based configuration file will take preference over the other.
Whenever we say, Configuration configuration = new Configuration().configure(), the no argument Configuration.configure() method will load the configuration file called “hibernate.cfg.xml” from the application’s classpath. The default name for the Hibernate Configuration file is “hibernate.cfg.xml”. Different configuration file can be loaded into the application by calling the one-argument Configuration.configure() method, like the following,
File configurationFile = new File(“.\\config\\MyConfiguration.xml”);
Configuration configuration = new Configuration().configure(configurationFile);
The code, SessionFactory sessionFactory = configuration.buildSessionFactory(), will populate the SessionFactory object with the set of property values values that are taken from the ‘session-factory’ XML element. So, in our case, the SessionFactory object will be populated with values the class name of the driver, the URL of the Database server and the username/password of the Database.
A Hibernate mapping file provides mapping information like how a Java Class is mapped to a relational database table. It also contains other information like which Java Property (or Field) in a class will map to which Table Column. Relations between entities can be defined in the Mapping file through various associations like one-to-one, one-to-many, many-to-many etc.
The mapping files that are needed for an application are defined and referenced in the Hibernate configuration file through the ‘mapping’ element.
Hibernate Entity / Persistence LifeCycle States
Hibernate will not be able to identify your java classes; but when they are properly annotated with required annotations then hibernate will be able to identify them and then work with them e.g. store in DB, update them etc. These classes can be said to mapped with hibernate.
Given an instance of an object that is mapped to Hibernate, it can be in any one of four different states: transient, persistent, detached, or removed.
Transient Object
Transient objects exist in heap memory. Hibernate does not manage transient objects or persist changes to transient objects.
To persist the changes to a transient object, you would have to ask the session to save the transient object to the database, at which point Hibernate assigns the object an identifier and marks the object as being in persistent state.

Persistent Object
Persistent objects exist in the database, and Hibernate manages the persistence for persistent objects.

If fields or properties change on a persistent object, Hibernate will keep the database representation up to date when the application marks the changes as to be committed.
Detached Object
Detached objects have a representation in the database, but changes to the object will not be reflected in the database, and vice-versa. This temporary separation of the object and the database is shown in image below.

A detached object can be created by closing the session that it was associated with, or by evicting it from the session with a call to the session’s evict() method.
One reason you might consider doing this would be to read an object out of the database, modify the properties of the object in memory, and then store the results some place other than your database. This would be an alternative to doing a deep copy of the object.
In order to persist changes made to a detached object, the application must reattach it to a valid Hibernate session. A detached instance can be associated with a new Hibernate session when your application calls one of the load, refresh, merge, update(), or save() methods on the new session with a reference to the detached object. After the call, the detached object would be a persistent object managed by the new Hibernate session.
Removed Object
Removed objects are objects that are being managed by Hibernate (persistent objects, in other words) that have been passed to the session’s remove() method. When the application marks the changes held in the session as to be committed, the entries in the database that correspond to removed objects are deleted.
Bullet Points
- Newly created POJO object will be in the transient state. Transient object doesn’t represent any row of the database i.e. not associated with any session object. It’s plain simple java object.
- Persistent object represent one row of the database and always associated with some unique hibernate session. Changes to persistent objects are tracked by hibernate and are saved into database when commit call happen.
- Detached objects are those who were once persistent in past, and now they are no longer persistent. To persist changes done in detached objects, you must reattach them to hibernate session.
- Removed objects are persistent objects that have been passed to the session’s remove() method and soon will be deleted as soon as changes held in the session will be committed to database.
Define Association Mappings between Hibernate Entities
Create one-to-one association between two simple entities
→ First technique is most widely used and uses a foreign key column in one to table.
→ Second technique uses a rather known solution of having a third table to store mapping between first two tables.
→ Third technique is something new which uses a common primary key value in both the tables.
- Using foreign key association
In this association, a foreign key column is created in owner entity. For example, if we make EmployeeEntity owner, then a extra column “ACCOUNT_ID” will be created in Employee table. This column will store the foreign key for Account table.
Table structure will be like this:
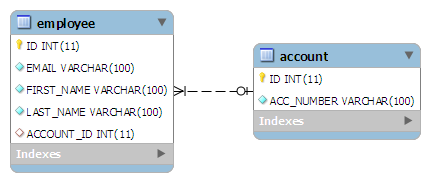
To make such association, refer the AccountEntity class in EmployeeEntity owner class as follow:
//EmployeeEntity
@OneToOne
@JoinColumn(name="ACCOUNT_ID", referencedColumnName=”ID”)
private AccountEntity account;
|
The join column is declared with the @JoinColumn annotation which looks like the @Column annotation. It has one more parameters named referencedColumnName. This parameter declares the column in the targeted entity that will be used to the join.
If no @JoinColumn is declared on the owner side, the defaults apply. A join column(s) will be created in the owner table and its name will be the concatenation of the name of the relationship in the owner side, _ (underscore), and the name of the primary key column(s) in the owned side.
In a bidirectional relationship, one of the sides (and only one) has to be the owner: the owner is responsible for the association column(s) update. To declare a side as not responsible for the relationship, the attribute mappedBy is used. mappedBy refers to the property name of the association on the owner side.
//AccountEntity
@OneToOne(mappedBy="account")
private EmployeeEntity employee;
Above “mappedBy” attribute declares that it is dependent on owner entity for mapping.
The annotation @JoinColumn indicates that this entity is the owner of the relationship (that is: the corresponding table has a column with a foreign key to the referenced table), whereas the attribute mappedBy indicates that the entity in this side is the inverse of the relationship, and the owner resides in the "other" entity. This also means that you can access the other table from the class which you've annotated with "mappedBy" (fully bidirectional relationship).
@Entity
public class Company {
@OneToMany(fetch = FetchType.LAZY, mappedBy = "company")
private List<Branch> branches; }
@Entity
public class Branch {
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "companyId")
private Company company; }
Using "mappedBy" attribute of mapping annotations(like @OneToOne, @OneToMany, @ManyToMany) for bi-directional relationship. This attribute allows you to refer the associated entities from both sides. If "X" has association with "Y" then you can get X from Y and Y from X.
For example, If you have "Book" entity and "Author" entity those are associated to each other in the way that Book has a Author and Author associated with a Book.
Now if you retrieve the Book Object from hibernate session, then you can get the Author entity from Book entity. Or if you get the Author entity then you can get the Book entity from Author entity.
So you require the bidirectional navigation relationships between Book and Author entities.
This is achieved in the Hibernate using the @OneToOne relationship provided that child entity must have property type of parent and marked with annotation @OneToOne(mappedBy="parent") where parent is the Owner entity of this child entity.
public static void main(String[] args) {
Session session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
AccountEntity account = new AccountEntity();
account.setAccountNumber("123-345-65454");
// Add new Employee object
EmployeeEntity emp = new EmployeeEntity();
emp.setEmail("demo-user@mail.com");
emp.setFirstName("demo");
emp.setLastName("user");
// Save Account
session.saveOrUpdate(account);
// Save Employee
emp.setAccount(account);
session.saveOrUpdate(emp);
session.getTransaction().commit();
HibernateUtil.shutdown();
}
}
Running above code creates desired schema in database and run these SQL queries.
Hibernate: insert into ACCOUNT (ACC_NUMBER) values (?)
Hibernate: insert into Employee (ACCOUNT_ID, EMAIL, FIRST_NAME, LAST_NAME) values (?, ?, ?, ?)
|
2) Using a common join table

In this technique, main annotation to be used is @JoinTable. This annotation is used to define the new table name (mandatory) and foreign keys from both of the tables.
@OneToOne(cascade = CascadeType.ALL)
@JoinTable(name="EMPLOYEE_ACCCOUNT", joinColumns = @JoinColumn(name="EMPLOYEE_ID"),
inverseJoinColumns = @JoinColumn(name="ACCOUNT_ID"))
private AccountEntity account;
|
@JoinTable annotation is used in EmployeeEntity class. It declares that a new table EMPLOYEE_ACCOUNT will be created with two columns EMPLOYEE_ID (primary key of EMPLOYEE table) and ACCOUNT_ID (primary key of ACCOUNT table)
3) Using shared primary key
In this technique, hibernate will ensure that it will use a common primary key value in both the tables. This way primary key of EmployeeEntity can safely be assumed the primary key of AccountEntity also.
Table structure will be like this:

In this approach, @PrimaryKeyJoinColumn is the main annotation to be used. Let see how to use it.
@OneToOne(cascade = CascadeType.ALL)
@PrimaryKeyJoinColumn
private AccountEntity account;
|
In AccountEntity side, it will remain dependent on owner entity for the mapping.
@OneToOne(mappedBy="account", cascade=CascadeType.ALL)
private EmployeeEntity employee;
|
Testing above entities generates following SQL queries in log files:
Hibernate: insert into ACCOUNT (ACC_NUMBER) values (?)
Hibernate: insert into Employee (ACCOUNT_ID, EMAIL, FIRST_NAME, LAST_NAME) values (?, ?, ?, ?)
|
So, we have seen all 3 types of one to one mappings supported in hibernate.
Create one-to-many association between two simple entities
First entity can have relation with multiple second entity instances but second can be associated with only one instance of first entity. Eg: in any company an employee can register multiple bank accounts but one bank account will be associated with one and only one employee.
- One is to have a foreign key column in account table i.e EMPLOYEE_ID. This column will refer to primary key of Employee table. This way no two accounts can be associated with multiple employees. Obviously, account number needs to be unique for enforcing this restriction.
- Another approach is to have a common join table let’s say EMPLOYEE_ACCOUNT. This table will have two column i.e. EMP_ID which will be foreign key referring to primary key in EMPLOYEE table and similarly ACCOUNT_ID which will be foreign key referring to primary key of ACCOUNT table.
Using foreign key association
In this approach, both entity will be responsible for making the relationship and maintaining it. EmployeeEntity should declare that relationship is One to many, and AccountEntity should declare that relationship from its end is many to one.
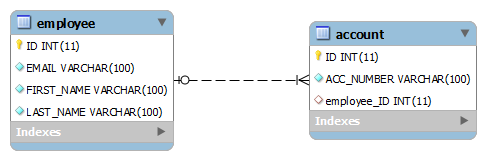
//EmployeeEntity
@OneToMany(cascade=CascadeType.ALL)
@JoinColumn(name="EMPLOYEE_ID")
private Set<AccountEntity> accounts;
//AccountEntity
@ManyToOne
private EmployeeEntity employee;
Create many-to-many association between two simple entities
Many to many mapping is made between two entities where one can have relation with multiple other entity instances. For example, for a subscription service SubscriptionEntity and ReaderEntity can be two type of entities. Any subscription can have multiple readers, where a reader can subscribe to multiple subscriptions.
Proposed solution
To demonstrate many to many mapping, we will associate two entities i.e. ReaderEntity and SubscriptionEntity. Their database schema should look like this. Using these tables, any application can save multiple associations between readers and subscriptions.

Writing owner entity
Owner entity is the entity which is responsible make making the association and maintaining it. In our case, I am making ReaderEntity the owner entity. @JoinTable annotation has been used to make this association.
//ReaderEntity
@ManyToMany(cascade=CascadeType.ALL)
@JoinTable(name="READER_SUBSCRIPTIONS", joinColumns={@JoinColumn(referencedColumnName="ID")}
, inverseJoinColumns={@JoinColumn(referencedColumnName="ID")})
private Set<SubscriptionEntity> subscriptions;
Writing mapped entity
Our mapped entity is SubscriptionEntity which is mapped to ReaderEntity using “mappedBy” attribute.
//SubscriptionEntity
@ManyToMany(mappedBy="subscriptions")
private Set<ReaderEntity> readers;
TYPE OF ASSOCIATION
|
OPTIONS/ USAGE
|
One-to-one
|
Either end can be made the owner, but one (and only one) of them should be; if you don’t specify this, you will end up with a circular dependency.
|
One-to-many
|
The many end must be made the owner of the association.
|
Many-to-one
|
This is the same as the one-to-many relationship viewed from the opposite perspective, so the same rule applies: the many end must be made the owner of the association.
|
Many-to-many
|
Either end of the association can be made the owner.
|
Hibernate can identify java objects as persistent only when they are annotated with certain annotations; otherwise they are treated as simple plain java objects with no direct relation to database.
Entities can contain references to other entities, either directly as an embedded property or field, or indirectly via a collection of some sort (arrays, sets, lists, etc.). These associations are represented using foreign key relationships in the underlying tables. These foreign keys will rely on the identifiers used by participating tables.
When only one of the pair of entities contains a reference to the other, the association is unidirectional. If the association is mutual, then it is referred to as bidirectional.
In hibernate mapping associations, one (and only one) of the participating classes is referred to as “managing the relationship” and other one is called “managed by” using ‘mappedBy’ property. We should not make both ends of association “managing the relationship”. Never do it.
While Hibernate lets us specify that changes to one association will result in changes to the database, it does not allow us to cause changes to one end of the association to be automatically reflected in the other end in the Java POJOs. We must use cascading capabilities for doing so.
JPA Lifecycle callback methods:-
What if we want entities to perform something when some operations are performed on entities?
How can we listen to the events performed on entities?
We can write JPA lifecycle callback methods by making use of annotations.
@PrePersist :- Entity is notified when em.persist() is successfully invoked on entity.
@PostPersist :- Notified when entity is persisted in database.
@PreUpdate :- Notified when entity is modified.
@PostUpdate :- Notified when updated state of entity is inserted in database
@PreRemove :- Notified when remove operation is called for entity by entity manager
@PostRemove:- Notified when entity is deleted from database.
Some rules need to be followed when annotating a method as jpa lifecycle callback methods.
- They can have any name
- The method signature should be such that return type is void and there are no parameters.
- They can have any access i.e. they can be private, default, protected or public.
- They cannot throw any checked exceptions.
@PrePersist
public void methodInvokedBeforePersist() {
System.out.println("Invoked before persisting employee");
}
@PostPersist
public void methodInvokedAfterPersist() {
System.out.println("Invoked after persisting employee");
}
⇒ em.persist(employee);
What is the difference between FetchType.LAZY and FetchType.EAGER in Java persistence?
EAGER = fetch the data immediately : fetched fully at the time their parent is fetched. So if you have Course and it has List<Student>, all the students are fetched from the database at the time the Course is fetched.
public class Course {
private String id;
private String name;
private String address;
private List<Student> students;
// setters and getters }
LAZY = fetch the data when needed OR on demand: LAZY on the other hand means that the contents of the List are fetched only when you try to access them. For example, by calling course.getStudents().iterator(). Calling any access method on the List will initiate a call to the database to retrieve the elements. This is implemented by creating a Proxy around the List (or Set). So for your lazy collections, the concrete types are not ArrayList and HashSet, but PersistentSet and PersistentList (or PersistentBag)
One big difference is that EAGER fetch strategy allows to use fetched data object without session. Why?
In case of lazy loading strategy, lazy loading marked object does not retrieve data if session is disconnected (after session.close() statement). All that can be made by hibernate proxy. Eager strategy lets data to be still available after closing session.
Hibernate JPA Annotations
In Hibernate 4 there are two ways to define an entity.
Either by defining an xml file hbm and map it with a bean
or instead just define a bean and use annotation for mapping with the table in DB like (@Entity, @column.. etc).
⇒ Using the annotations you're binding your model (entities) to the Hibernate framework fairly tightly (you're introducing coupling between them). On the other hand your source code becomes much more readable since you don't have to switch forth between the XMLs and the Java sources files.
Originally Hibernate supported only the XML mappings and annotations were added later (after they were introduced in Java 5). Most Java developers favor heavily the annotations since they really make it apparent that a class represents a Hibernate entity, what constraints it has and how it relates to other entities in the application. On the other hand using the XML definitions decouples your source from Hibernate and you can easily switch to another library without modifying the Java sources. You'd do much better with the use of the Java Persistence API and it's portable annotations, though. It give to the ability to use an unified ORM API that can delegate to any ORM framework (Hibernate, ibatis, EclipseLink, etc). Switching between frameworks is easy as changing on line in JPA's configurations and adding the new ORM to your project's classpath. In practice very few companies use Hibernate directly (unless they need some of its unique features) - it's generally used in combination with JPA. Very few people use the XML entity definitions as well - I haven't worked on a project with them in quite a while.
While working with Hibernate web applications we will face so many problems in its performance due to database traffic. So some techniques are necessary to maintain its performance. Hibernate Caching is the best technique to solve this problem.
The cache actually stores the data already loaded from the database, so that the traffic between our application and the database will be reduced when the application want to access that data again.
Maximum the application will works with the data in the cache only. Whenever some other data is needed, the database will be accessed. Because the time needed to access the database is more when compared with the time needed to access the cache. So obviously the access time and traffic will be reduced between the application and the database. Here the cache stores only the data related to current running application.
Hibernate uses two different caches for objects: first-level cache and second-level cache.
1.1) First-level cache
First-level cache always Associates with the Session object. Hibernate uses this cache by default. Here, it processes one transaction after another one, means won't process one transaction many times. Mainly it reduces the number of SQL queries it needs to generate within a given transaction. That is instead of updating after every modification done in the transaction, it updates the transaction only at the end of the transaction.
1.2) Second-level cache
Second-level cache always associates with the Session Factory object. While running the transactions, in between it loads the objects at the Session Factory level, so that those objects will available to the entire application, don’t bounds to single user. Since the objects are already loaded in the cache, whenever an object is returned by the query, at that time no need to go for a database transaction. In this way the second level cache works. Here we can use query level cache also.
Controller | Service layer/Manager | DAO layer | DB
Hibernate with Spring Integration



you are a copy paste king
ReplyDelete