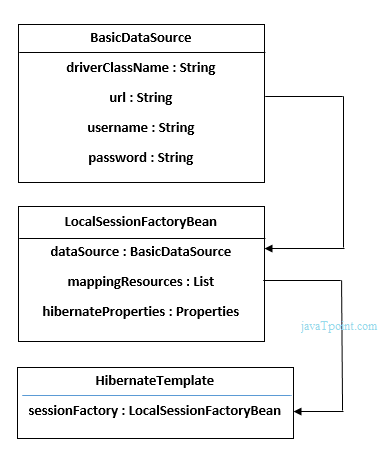
Functions - may or may not return a value.
function declaration
function function_name(){
// statements
};
var c = function_name();
console.log(c);
function expression
var function_name = function(){
//statements
};
var c = function_name();
console.log(c);
Methods - when function is an object's property
var calc = {
add : function(a,b) {
return a+b
},
sub : function(a,b){
return a-b
}
}
calc => object
add,sub => method
calc.add(1,2);
calc.sub(3,2);
Constructors - when you add new keyword before a function and call it, it becomes a constructor that create instances.
function fruit(){
var name,family;
this.getName = function(){
return name;
};
this.setName = function(value){
name=value;
};
}
var apple = new fruit();
apple.setName("Malus");
console.log(apple.getName());
function as a parameter
function f1(val){
return val.toUpperCase();
}
function f2(val,passFunc){
console.log(passFunc(val));
}
f2("small",f1);
// string, reference
Scope
global/public
local/private
global variable
- place a var statement outside any function
- omit var statement
local variable
- variables declared within a function
this parameter
refers to an object that's implicitly associated with function invocation
invocation as a function
- 'this' is bound to global object(window)
invocation as a method
- 'this' is bound to object
invocation as a constructor
Create JavaScript Object
object literal => similar to JSON format
var author ={
// variables
firstName : "Megha",
lastName : "Dureja",
book : {
title : "JS",
pages : "172"
}
// method
meetingRoom : function(roomId){
console.log("BookedRoom");
}
};
console.log(author.lastName);
console.log(author.book.title);
object constructor
var author = new Object();
function constructor
prototype
function/prototype combination
singleton
Variable / Object
variable - container for data value
var car = "Polo";
Object - container for many value and methods to perform action
<script>
var car = {
type : "Polo",
model : "500",
color : "white"
fullName : function(){
return this.type + "" + this.model + "" +this.color;
}
};
</script>
function declaration
function function_name(){
// statements
};
var c = function_name();
console.log(c);
function expression
var function_name = function(){
//statements
};
var c = function_name();
console.log(c);
Methods - when function is an object's property
var calc = {
add : function(a,b) {
return a+b
},
sub : function(a,b){
return a-b
}
}
calc => object
add,sub => method
calc.add(1,2);
calc.sub(3,2);
Constructors - when you add new keyword before a function and call it, it becomes a constructor that create instances.
function fruit(){
var name,family;
this.getName = function(){
return name;
};
this.setName = function(value){
name=value;
};
}
var apple = new fruit();
apple.setName("Malus");
console.log(apple.getName());
function as a parameter
function f1(val){
return val.toUpperCase();
}
function f2(val,passFunc){
console.log(passFunc(val));
}
f2("small",f1);
// string, reference
Scope
global/public
local/private
global variable
- place a var statement outside any function
- omit var statement
local variable
- variables declared within a function
this parameter
refers to an object that's implicitly associated with function invocation
invocation as a function
- 'this' is bound to global object(window)
invocation as a method
- 'this' is bound to object
invocation as a constructor
Create JavaScript Object
object literal => similar to JSON format
var author ={
// variables
firstName : "Megha",
lastName : "Dureja",
book : {
title : "JS",
pages : "172"
}
// method
meetingRoom : function(roomId){
console.log("BookedRoom");
}
};
console.log(author.lastName);
console.log(author.book.title);
object constructor
var author = new Object();
function constructor
prototype
function/prototype combination
singleton
Variable / Object
variable - container for data value
var car = "Polo";
Object - container for many value and methods to perform action
<script>
var car = {
type : "Polo",
model : "500",
color : "white"
fullName : function(){
return this.type + "" + this.model + "" +this.color;
}
};
</script>